![]()
동기
MCP(Model Context Protocol)의 등장 이후 AI 에이전트와 외부 도구의 연동이 화두가 되면서, CLI 도구들도 새롭게 주목받기 시작했다. cli-anything 같은 CLI 카탈로그가 생겨나고, 에이전트가 직접 터미널 명령을 실행하는 흐름이 자리 잡고 있다.
물론 에이전트도 웹 검색을 할 수 있다. "best CLI tool for CSV to JSON"을 검색하면 답은 나온다. 하지만 웹 검색에는 비용이 따른다:
- 느리다: 웹 검색 API 호출 → 결과 페이지 파싱 → 관련 정보 추출의 왕복이 필요하다
- 비용이 든다: 검색 API 토큰이나 크레딧을 소모한다
- 비결정적이다: 같은 쿼리라도 SEO, 광고, 시점에 따라 결과가 달라진다
- 구조화되지 않았다: 블로그 글이나 Reddit 댓글에서 설치 명령어를 추출해야 한다
반면 로컬 CLI 도구라면 즉시 응답하고, 항상 같은 스키마의 구조화된 결과를 반환하며, 오프라인에서도 동작한다. Claude Code로 코딩하다 보면 에이전트가 grep이나 find 같은 기본 명령어는 자연스럽게 쓰지만, 더 좋은 대안 도구의 존재를 모른다. grep 대신 ripgrep을, find 대신 fd를, cat 대신 bat을 쓸 수 있다는 걸 에이전트가 알면 작업 효율이 올라간다.
에이전트가 필요로 하는 건:
- 검색: "CSV를 JSON으로 변환하는 도구?" →
jq,miller,csvkit - 메타데이터: 설치 방법, GitHub stars, 문서 링크
- 비교:
jqvsdaselvsyq- 뭐가 다른지 - 구조화된 출력: 사람이 읽는 텍스트가 아니라, 파싱 가능한 YAML/JSON
이 네 가지를 해결하는 LLM/에이전트를 위한 CLI 도구 검색기를 만들기로 했다.
기존 카탈로그와의 차이
cli-anything이나 awesome-cli-apps 같은 기존 카탈로그는 사람이 브라우징하는 것을 전제로 만들어져 있다. LLM이 마크다운을 읽는 건 어렵지 않지만, 문제는 구조화된 메타데이터가 없다는 것이다. 설치 명령어, stars, 문서 링크 같은 정보가 파싱 가능한 형태로 제공되지 않으면 에이전트가 "이 도구를 설치해서 써보자"는 판단을 자동화하기 어렵다.
AI 에이전트가 CLI 도구를 활용하려면 아래 흐름을 자동으로 수행할 수 있어야 한다:
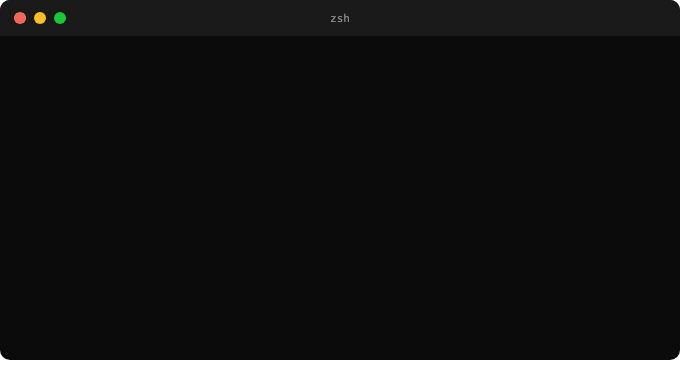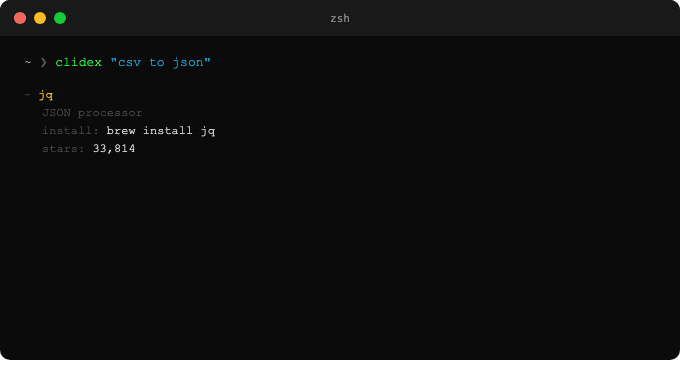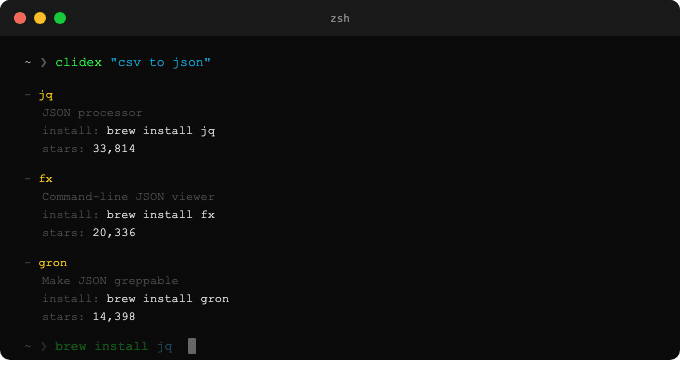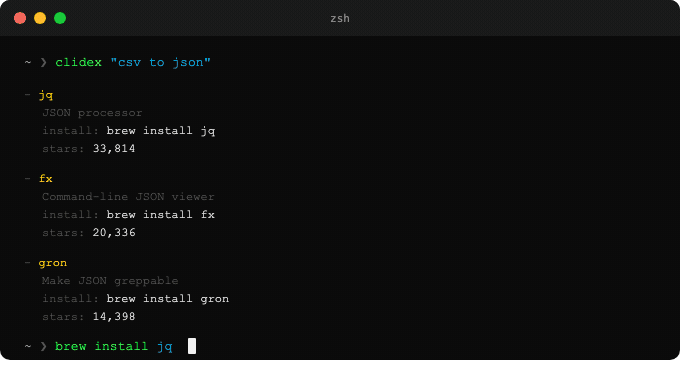
에이전트가 clidex "csv to json"을 실행하면 구조화된 YAML 결과를 받고, install 필드에서 명령어를 추출해 바로 설치한다.
이 파이프라인에서 Clidex가 담당하는 건 "어떤 도구가 있고, 어떻게 설치하는지"를 구조화된 데이터로 알려주는 것이다. 에이전트는 구글링을 할 수 없지만, CLI 명령은 실행할 수 있다. Clidex는 그 간극을 메운다.
핵심 차별점:
| cli-anything / awesome-cli-apps | Clidex | |
|---|---|---|
| 타겟 사용자 | 사람 | AI 에이전트 (+ 사람) |
| 출력 형태 | TUI / 마크다운 | YAML / JSON / Pretty |
| 설치 정보 | 링크만 | brew install jq 명령어 직접 제공 |
| 문서 접근 | 사람이 클릭 | llms.txt 링크로 에이전트가 직접 읽기 |
| 파이프라인 | 불가능 | clidex ... | agent_tool (기본 YAML) |
| 비교 기능 | 없음 | clidex compare jq dasel yq |
특히 llms.txt 링크가 중요하다. llms.txt는 LLM이 프로젝트를 이해할 수 있도록 마크다운으로 제공하는 표준이다. Clidex는 도구의 llms.txt URL을 인덱싱하므로, 에이전트가 도구를 찾은 뒤 문서까지 자동으로 읽고 사용법을 학습할 수 있다.
설계 원칙
Agent-first → 출력이 기계가 읽기 쉬운 YAML/JSON
Link-based → 콘텐츠를 호스팅하지 않고 링크만 제공 (repo, docs, llms.txt)
Curated index → 무작정 크롤링이 아니라 검증된 소스에서 수집
Pipeline-native → clidex "jq" | 다른_도구 로 체이닝 가능 (기본 YAML)
데이터 소스
어디서 도구 데이터를 가져올지가 첫 번째 결정이었다.
| 소스 | 장점 | 단점 | 채택 |
|---|---|---|---|
| awesome-cli-apps | 사람이 큐레이션, 카테고리 분류 완비 | ~426개 한정, 일부 인기 도구 누락 | O (1차 소스) |
| Homebrew formula.json | 8,200+ formulae, 벌크 API | CLI/lib 구분 필요 | O (보강 소스) |
| GitHub API | stars, last_updated | rate limit 60/hr (토큰 없이) | O (메타데이터) |
| crates.io | Rust CLI 생태계 | repo URL 매칭 필요 | O (install 보강) |
| npm | Node CLI 생태계 | bin 필드 확인 필요 | O (install 보강) |
| Repology | 크로스 패키지매니저 | API가 불안정 | X |
최종적으로 awesome-cli-apps를 기본 뼈대로 하고, Homebrew로 빠진 인기 도구를 보강하는 전략을 택했다. 파서가 awesome-cli-apps의 427개 중 427개를 파싱하고(99.8%), Homebrew에서 tmux, hyperfine, htop 등 15개 인기 도구를 추가로 가져와 총 440개 도구를 인덱싱한다.
설치 명령어는 3개 소스에서 수집한다:
- Homebrew: 이름 매칭으로
brew install명령어 자동 추가 (186개 매치) - crates.io: GitHub repo URL 비교 + 알려진 27개 Rust CLI 매핑으로
cargo install추가 (42개) - npm: 알려진 Node CLI 패키지의
bin필드 확인으로npm install -g추가 (12개)
# ripgrep 예시 - 3가지 설치 방법 제공
install:
brew: brew install ripgrep
cargo: cargo install ripgrepCLI 필터링 휴리스틱
Homebrew에는 CLI 도구와 라이브러리가 섞여 있다. 전체 8,278개 formula 중 CLI 도구만 걸러내야 했다.
fn is_likely_cli(formula: &BrewFormula) -> bool {
// 1. keg_only면 보통 라이브러리
if formula.keg_only { return false; }
// 2. 설명에 라이브러리 키워드 → 제외
// "library", "bindings", "header files" 등
// 3. CLI 키워드 → 포함
// "command-line", "terminal", "tui" 등
// 4. 동작 동사 → 포함
// "manage", "monitor", "search", "convert" 등
// 5. 기본값: 포함 (Homebrew는 CLI 비중이 높음)
true
}결과: 6,909개를 CLI로 분류 (83%). 검증 결과:
| 케이스 | 정확도 |
|---|---|
| 알려진 CLI 도구 10개 (jq, ripgrep, fzf 등) | 9/10 (curl만 미스) |
| 알려진 라이브러리 6개 (openssl, boost 등) | 3/6 |
라이브러리 분류 정확도가 낮지만, 현재는 수동 리스트(wanted)로 확실한 도구만 추가하고 있어 실제 인덱스에는 영향 없다. 향후 역방향 의존성 수(다른 패키지가 이 패키지를 얼마나 의존하는지)를 추가하면 정확도를 높일 수 있다 - 의존성이 많으면 라이브러리, 적으면 최종 사용자 도구일 확률이 높다.
검색 전략: 무엇을 고려했나
이 프로젝트에서 가장 많이 고민한 부분이 검색이다. CLI 도구 440개에서 자연어 쿼리로 관련 도구를 찾아야 한다.
후보 1: 임베딩 모델
처음 생각한 건 의미 검색(semantic search)이었다. "CSV를 JSON으로 바꾸는 도구"라는 쿼리와 "tabular data processor"라는 설명 사이의 의미적 유사도를 잡을 수 있으니까.
조사한 모델들:
| 모델 | 크기 | 특징 |
|---|---|---|
| Model2Vec (distilled) | ~30MB | 영어 전용, 빠름 |
| MiniLM-L6 (ONNX) | ~25MB | 다국어 가능 |
| all-MiniLM-L6-v2 | ~80MB | sentence-transformers 기반 |
결론: 도입하지 않았다. 이유:
- 크기 대비 효과가 미미하다. 440개 문서에서 BM25만으로도 충분한 recall이 나온다. 임베딩 모델은 수천~수만 문서에서 진가를 발휘한다.
- 배포 크기가 커진다. Clidex 바이너리가
2MB인데, 임베딩 모델을 넣으면 3080MB가 된다. CLI 도구치곤 너무 크다. - 2~5% 개선에 30MB를 쓸 이유가 없다. BM25 + 좋은 태그 + 시노님 확장으로 이미 93%+ recall이 나온다.
"더 좋은 기술"이 항상 "더 나은 선택"은 아니다. 440개 문서 인덱스에 BERT를 넣는 건 파리를 잡는데 대포를 쓰는 격이다. 문제의 규모에 맞는 도구를 선택해야 한다.
후보 2: BM25 + 도메인 최적화
BM25는 전통적인 텍스트 검색 알고리즘이다. TF-IDF의 확장판으로, 문서 길이 정규화와 용어 빈도 포화(saturation)를 추가한 것.
핵심 아이디어: BM25 자체는 평범하지만, 입력 데이터를 잘 가공하면 성능이 크게 올라간다.
이 접근을 선택했다.
현재 검색 아키텍처
1. 빌드 타임: 태그 생성
인덱스를 빌드할 때 각 도구에 검색용 태그를 자동 생성한다.
도구: ripgrep
설명: "A line-oriented search tool that recursively searches..."
카테고리: Files and Directories > Search
→ 태그: [files, directories, search, line-oriented, tool, recursively,
ripgrep, rg] ← 알려진 alias 자동 추가
태그 소스 3가지:
- 카테고리 단어 (stopword 제외)
- 설명 키워드 (stopword 제외)
- 알려진 alias (ripgrep→rg, bat→batcat 등 24쌍)
2. 쿼리 타임: BM25 + 시노님 + 리랭킹
쿼리: "csv to json"
↓
① 시노님 확장 (원본 2x 가중)
→ "csv csv to to json json comma-separated tabular spreadsheet tsv jq structured-data"
↓
② BM25 검색 (상위 50개 후보)
↓
③ 리랭킹
- 이름 정확 매치: +50점
- 바이너리 이름 매치: +45점
- 카테고리 매치: +8점 × 매칭 단어 수
- 인기도 부스트: stars 기반 0~10점
↓
④ 상위 N개 반환
필드 가중치 (텍스트 반복으로 구현)
BM25 crate가 필드별 가중치를 지원하지 않아서, 텍스트 반복으로 우회했다.
fn build_search_text(tool: &Tool) -> String {
// 이름 3x - 가장 중요
// 카테고리 + 태그 2x
// 설명 1x
}시노님 맵 (~50개 엔트리)
CLI 도메인에 특화된 시노님을 수동으로 관리한다.
("grep", &["search", "find", "ripgrep", "rg"]),
("benchmark", &["bench", "performance", "speed", "measure", "hyperfine"]),
("container", &["docker", "podman", "kubernetes", "k8s"]),
("disk", &["storage", "space", "du", "usage"]),초기에 "benchmark" → "time"이라는 시노님을 넣었다가, "benchmark" 검색 시 시간 추적(time tracking) 도구가 상위에 오는 문제가 발생했다. "diff" → "compare" 시노님도 "compare movies"라는 설명을 가진 movie 도구를 git diff 검색에 끌어올렸다. 시노님은 recall을 올리지만 precision을 떨어뜨릴 수 있다. 도메인 특화된 시노님만 유지하는 것이 핵심이다.
카테고리 부스트
쿼리 단어가 도구의 카테고리명에 포함되면 추가 점수를 준다. 예를 들어 "file manager" 쿼리에서 Files and Directories > File Managers 카테고리의 도구들이 부스트를 받는다.
stem-like 매칭을 사용해서 "manager"와 "managers"가 매칭된다.
cat_words.iter().any(|cw| cw.starts_with(term) || term.starts_with(cw))짧은 쿼리 처리
rg, fd 같은 2~3글자 쿼리는 BM25에서 잘 안 잡힌다. 두 가지로 보완:
- 태그 exact match: 태그에 "rg"가 있으면 +20점 부스트
- fuzzy threshold 상향: 3글자 이하 쿼리는 fuzzy match threshold를 50→80으로 올려서 "htop"이 "http prompt"에 매칭되는 것을 방지
테스트 결과
단위 테스트: 30개 쿼리, 100% recall
20개 모의 도구에 대해 easy/medium/hard 난이도로 분류한 30개 쿼리를 테스트한다.
| 난이도 | 예시 쿼리 | 기대 결과 | 결과 |
|---|---|---|---|
| Easy | jq | jq (top 1) | PASS |
| Easy | dns lookup | dog (top 3) | PASS |
| Medium | csv data processing | miller or csvkit (top 5) | PASS |
| Medium | better ls command | eza (top 5) | PASS |
| Hard | what is eating my disk space | ncdu or dust (top 5) | PASS |
| Hard | cat replacement with colors | bat (top 5) | PASS |
성능: 2.6ms/query (20개 도구 기준, 목표 50ms 이하)
E2E 테스트: 21개 실사용 쿼리, 100%
실제 440개 도구 인덱스에 대해 실사용 시나리오를 테스트했다.
| 쿼리 | Top 5 결과 | 판정 |
|---|---|---|
rg | ripgrep | PASS |
htop | htop, HTTP Prompt | PASS |
csv to json | q, strip-json-comments-cli, jp, gron, fx | PASS |
git diff | git-delta, git-extras, git commander... | PASS |
file manager | far2l, Vifm, clifm, yazi, lf | PASS |
terminal multiplexer | tmux, zellij, tmate, warp, gotty | PASS |
benchmark | hyperfine, speed-test, speedtest-net | PASS |
http client | curlie, xh, ain, ATAC, HTTP Prompt | PASS |
shell prompt | starship, intelli-shell, nushell, fish | PASS |
password manager | pass, gopass | PASS |
docker | docker-pushrm, lazydocker, dockly, lstags, ctop | PASS |
kubernetes | k9s | PASS |
better ls | eza, lsd, np, duf, ll | PASS |
download video | youtube-dl, streamlink, mpv | PASS |
disk space | diskonaut, dust, dua-cli, NCDu, duf | PASS |
json processor | jq, jc, dasel, GROQ, yq | PASS |
fuzzy finder | fjira, fzf, television, happyfinder | PASS |
bat | bat, bats-core | PASS |
fd | fd | PASS |
password manager | pass, gopass | PASS |
htop | htop | PASS |
이전 버전과의 비교
검색 개선 전후의 변화:
| 쿼리 | 개선 전 | 개선 후 | 원인 |
|---|---|---|---|
rg | (0 결과) | ripgrep | alias 태그 추가 |
git diff | movie (false positive) | git-delta | "diff→compare" 시노님 제거 |
benchmark | dev-time (time tracking) | hyperfine | "benchmark→time" 시노님 제거 + Homebrew 보강 |
file manager | beets (music library) | far2l, Vifm, clifm | 카테고리 부스트 + BM25 후보 풀 확대 |
terminal multiplexer | cmus (music player) | tmux, zellij | "terminal→console" 시노님 제거 + Homebrew 보강 |
htop | HTTP Prompt | htop | Homebrew에서 htop 추가 |
기술 스택
| 레이어 | 기술 | 이유 |
|---|---|---|
| 언어 | Rust | 빠른 바이너리, 크로스 컴파일 용이 |
| 검색 | bm25 crate | 순수 Rust, 외부 의존성 없음 |
| Fuzzy matching | fuzzy-matcher (skim) | 오타 허용, 이름 검색 |
| CLI | clap derive | 선언적 CLI 구조 |
| 직렬화 | serde + serde_yaml + serde_json | YAML/JSON 듀얼 출력 |
| HTTP | reqwest (rustls) | OpenSSL 의존성 제거 |
| 빌드 크기 | opt-level z + LTO + strip | ~2MB 바이너리 |
설치
curl -fsSL https://raw.githubusercontent.com/syshin0116/clidex/main/install.sh | sh플랫폼(linux/mac, x86/arm)을 자동 감지해서 맞는 바이너리를 ~/.local/bin에 설치한다. 설치 후 인덱스를 받아야 사용할 수 있다:
clidex update # ~/.clidex/index.yaml 다운로드명령어 가이드
clidex <query> - 검색
가장 핵심 기능. 자연어 쿼리로 CLI 도구를 검색한다.
clidex "csv to json" # YAML 출력 (기본값, 에이전트용)
clidex "csv to json" --pretty # Pretty 출력 (사람용)
clidex "csv to json" --json # JSON 출력
clidex "file manager" -n 3 # 상위 3개만기본 출력이 YAML이므로 에이전트는 플래그 없이 바로 사용할 수 있다:
- name: jq
desc: JSON processor
category: Data Manipulation > Processors
tags: [data, manipulation, processors, json, jq]
install:
brew: brew install jq
links:
repo: https://github.com/stedolan/jq
homepage: https://jqlang.github.io/jq/에이전트는 이 결과에서 install.brew 값을 꺼내 바로 실행하면 된다.
clidex info <name> - 도구 상세 정보
특정 도구의 전체 메타데이터를 조회한다.
clidex info jq # YAML 출력 (기본값)
clidex info jq --pretty # 사람이 읽기 좋은 형태에이전트가 도구를 선택한 후 설치 방법, 문서 링크, llms.txt URL 등을 확인할 때 사용한다.
clidex compare <name1> <name2> [name3...] - 도구 비교
비슷한 용도의 도구들을 side-by-side로 비교한다. 에이전트가 여러 후보 중 하나를 선택할 때 유용하다.
clidex compare jq dasel yq # YAML 출력 (기본값)
clidex compare jq dasel yq --pretty # 테이블 형태--pretty 사용 시:
jq dasel yq
────────────────────────────── ────────────────────────────── ──────────────────────────────
Description JSON processor JSON/YAML/TOML/XML processor … YAML processor
Category Processors Processors Processors
Stars ★ 33.8k ★ 7.9k ★ 2.9k
Install brew install jq brew install dasel brew install yq
Updated 2026-03-11 2026-03-10 2026-01-02
Repo https://github.com/stedolan/jq https://github.com/tomwright/… https://github.com/kislyuk/yq
존재하지 않는 도구가 포함되면 Warning을 출력하고 있는 것만 비교한다.
clidex trending - 인기 도구
GitHub stars 기준으로 인기 도구를 보여준다.
clidex trending -n 10 # 전체 상위 10개
clidex trending --category git # Git 관련 인기 도구
clidex trending --pretty # 사람용 테이블stars 데이터가 있어야 동작한다. 인덱스 빌드 시 GITHUB_TOKEN 환경변수를 설정하면 전체 도구의 stars를 수집한다.
clidex --categories - 카테고리 목록
인덱스에 있는 모든 카테고리와 도구 수를 보여준다.
clidex --categories
clidex --categories --prettyclidex --category <name> - 카테고리 필터
특정 카테고리의 도구만 필터링한다. stars 기준으로 정렬된다.
clidex --category docker
clidex --category "file manager" -n 5검색과 달리 BM25를 거치지 않고 카테고리명에 대한 부분 문자열 매칭을 한다. "file manager"로 검색하면 Files and Directories > File Managers 카테고리 전체가 나온다.
clidex update - 인덱스 업데이트
GitHub Release에서 최신 인덱스를 다운로드한다.
clidex update
# Index updated: 440 toolsclidex stats - 인덱스 통계
현재 로컬 인덱스의 상태를 확인한다.
clidex stats
# Index version: 1
# Generated: 2026-03-14T08:58:23Z
# Total tools: 440
# Categories: 76
# With install: 228
# With stars: 395
# With docs: 0
# With llms.txt: 1출력 포맷
| 플래그 | 포맷 | 설명 |
|---|---|---|
| (없음) | YAML | 기본값. 구조화된 에이전트 친화적 포맷 |
--pretty | Pretty | 사람이 읽기 좋은 테이블 포맷 |
--json | JSON | 프로그래밍적 파싱용 JSON |
에이전트는 플래그 없이 바로 YAML을 받아 파싱할 수 있다.
기타 플래그
| 플래그 | 설명 |
|---|---|
-n <N> | 최대 결과 수 (기본 10) |
CI/CD
| Workflow | 트리거 | 역할 |
|---|---|---|
ci.yml | push/PR to main | cargo check + test + clippy + fmt |
release.yml | v* 태그 | 5 플랫폼 크로스 컴파일 → GitHub Release |
build-index.yml | 매주 월요일 | 인덱스 자동 빌드 → Release 업로드 |
build-index.yml이 핵심이다. GitHub Actions runner에서 build_index를 돌리고, 결과 index.yaml을 GitHub Release에 올린다. 사용자는 clidex update로 최신 인덱스를 받아온다.
아직 남은 것들
- llms.txt 발견율 향상: 현재 구현됐으나 llms.txt를 제공하는 CLI 프로젝트가 아직 적음
- 역방향 의존성 기반 CLI 필터링: Homebrew
usesAPI로 라이브러리/CLI 구분 정확도 향상 - GitHub stars 완전 수집: GITHUB_TOKEN으로 rate limit 해제 후 전체 도구 stars 수집
- Homebrew 30일 설치 수: Homebrew Analytics API에서 인기도 데이터 수집
마치며
Clidex를 만들면서 가장 많이 배운 건 **검색은 데이터가 80%**라는 것이다. BM25든 임베딩이든, 도구 이름에 "rg" alias가 없으면 "rg" 검색이 안 되고, htop이 인덱스에 없으면 아무리 좋은 알고리즘도 소용없다. 알고리즘 튜닝보다 데이터 품질 개선(태그 추가, alias 매핑, 누락 도구 보강)이 검색 품질에 훨씬 더 큰 영향을 미쳤다.
- GitHub: syshin0116/clidex
- crates.io: clidex